To continue this trend of playing with AI tools to speed up developer content production (see previous Fundo Fridays), today I'll be showing you how good ElevenLabs is.
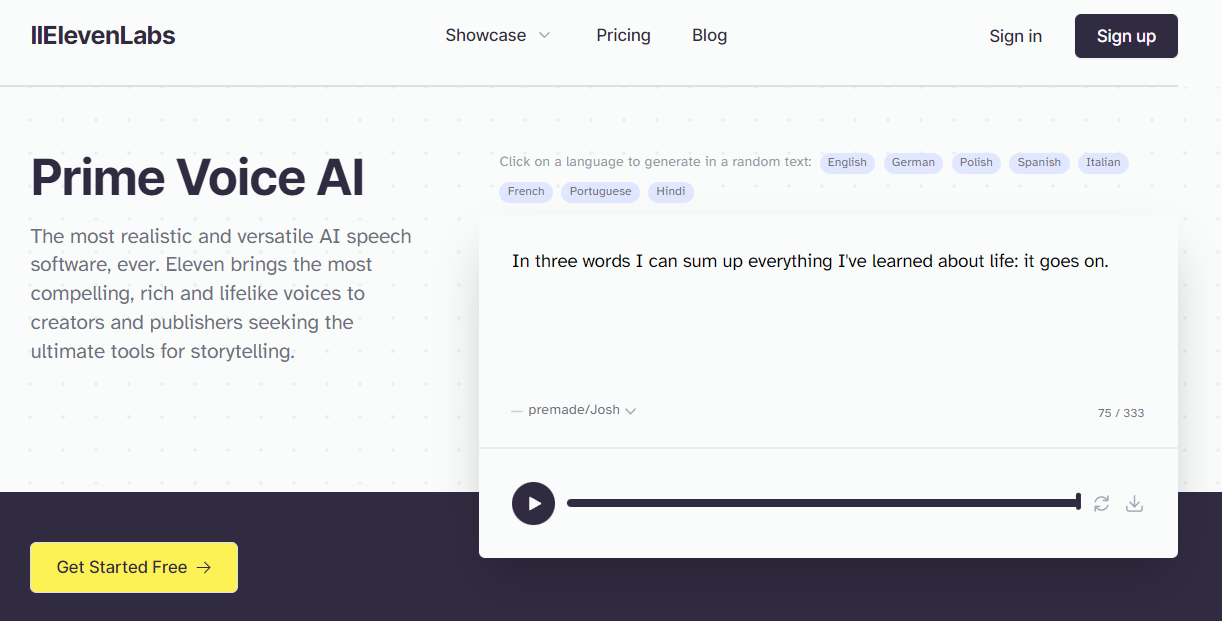
ElevenLabs is an AI text-to-speech (TTS) service that has really good trained voices (and lets you train your own) – importantly, it offers a programmable API to generate text-to-speech.

Previously, I did a short bit on using Descript's Overdub with my own voice. It was OK but probably needs a lot more training.

Today, we'll just be using two of the built-in AI voices from ElevenLabs: Rachel and Josh. These two are the best IMHO but like Descript, you can train your own.
Providing the script
If you want to play for free, you can make around 5 samples right on the homepage.
Once you create an account (you can start free), you can provide longer text. The free account gives you about 6,000 characters worth of conversion, so it's not a ton and you'll use it up fast.
As a sample, I had Rachel read my Developer Pour-Over post, so check it out:
Here's another sample with Josh, one of my other preferred voices explaining stress like I'm 5:
I don't know about you but I would say that's pretty damn good.
Things it can do:
- Adjust tone when quoting
- Sigh or laugh
- Adjust rhythm
If I didn't tell you it was AI, it would be pretty convincing. And that means for your end-users, they probably can't tell (or care, as long as it's understandable).
Here are the settings I used to get a more natural-sounding cadence and voice:
- Stability: 30-35% (More pausing, variability in rhythm and tone but not overly so)
- Clarity: 85% (More articulate)
- Eleven Monolingual v1
Text-to-speech enables a lot of cool things in the developer space, like reading docs aloud or automatically generating podcasts from a blog/newsletter, etc.
But one workflow it could REALLY speed up is video creation.
There's a certain kind of video this could work well for and that's tutorials or step-by-step guides. I like to make them as companions to written guides but videos ALWAYS incur higher maintenance – if anything changes, you need to update them. By not having to record my own voice and using a script, it would be much easier to keep videos updated. That's why you'll often see YouTube videos without any dialogue or voice and just using captions – it's a lot of work to make a script and talk over demos.
Overlaying Script with Video
Since part of my video creation process is scripting, it's not hard for me to plug a script into ElevenLabs, download it, and use it as an audio track for a video.
I wanted to see how well the AI handles technical content and jargon. So here's a clip from my upcoming Pluralsight course on React Debugging that is pretty heavy with specialized language. I also want to test its ability with humor, since I tend to joke around (debugging is boring).
This is a fully produced clip that I'll be using for the course about revealing React hook names (it's about 1 minute long):
As you can hear, I've got two jokes in there with varying tone, as well as some technical jargon ("BugNet" component, "useContext" hook name, etc.)
In Camtasia, I've got my audio on its own track along with the video:
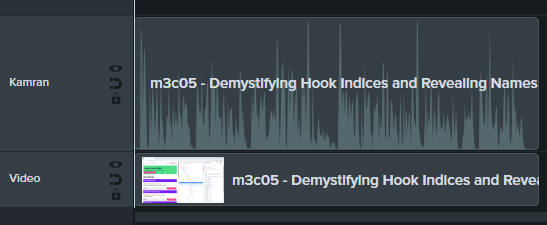
Here is the script I plugged into ElevenLabs:
But hang on -- how come the BugNet doesn't have an index? After all, it's still using useContext which is a hook.
If you said, "Because it's the first one," that's a good guess, but if I go over to the TextInput, which has way more hooks, you can see it's not _just_ because of that.
In fact, useContext, while being a hook, does not have any internal state that React needs to keep track of.
That means it's not just ANY hook that gets assigned an index, it's any hook *that needs to be tracked*.
So now you know how to correlate hooks in the dev tools with your component source code – they appear in the same order. But JUST the index is still not great, it would be better to actually show the variable names for each hook because that's how you refer to them in the code.
By default, hook names aren't parsed so you have to click this magic wand icon. But we can turn on global parsing of hook names in the Options. It warns us here that it's going to be slow, but hey, we're React developers, we're used to that. Hehehe ok yeah just kidding.
Now when I navigate around the tree, the parsed names show up in the hook in parenthesis, with a bit more faded text.
Like the hook is whispering its name faintly. It's like in Harry Potter. No, those aren't voices you hear, you now can speak "parsing hook tongue."Using the same settings as earlier, I generated the audio using Rachel's voice and added it as a new track to the video.
How well did it match up with my original cadence and rhythm? Not too bad, about 5 seconds short.
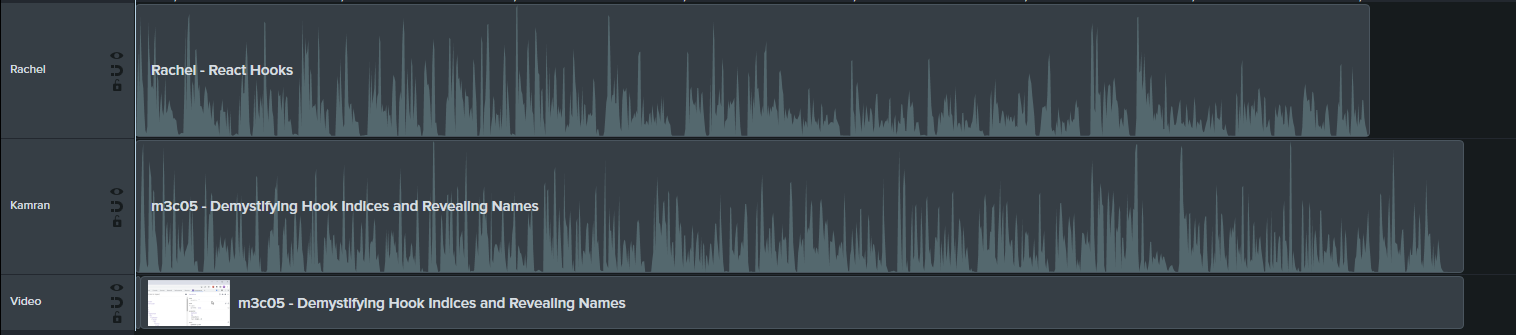
That means I would have to do some light editing, adjusting the video to match the new cadence.
Listen to Rachel the React Developer
Take a look at the result:
Everything actually goes really great UNTIL it encounters my first joke. I'll let you listen but it falls completely on its face trying to laugh.
Adjusting tone and regeneration
Can we try to adjust that piece only? I tried a few variations and the ones I liked were:
ElevenLabs uses the context around the sentence to try and determine the tone – so I think by adding "joking" it understood to make it more jovial and it did a decent job. This means that every time you click "Regenerate" you will get a different-sounding result. This is great but also sucks because it uses up credits.
And how about the last bit, my dad joke about "parsing hook tongue"? It's too flat and doesn't come off right.
I tried playing with the variability and sentence structure.
Here's one with 15% variability:
Like the hook is whispering its name, faintly... it's like in Harry Potter. No, those aren't voices you hear... you now can speak "parsing hook tongue."That was OK but I think I got the best with a 35% variability and tweaking the script:
It's as if the hook is whispering its name, faintly... you know, like Harry Potter. No... those aren't VOICES you hear -- you now can speak "Parsing Hook Tongue."Capitalizing helps indicate emphasis (sometimes).
Put it all together with the two updates and now we have something workable!
In my opinion, this is "good enough" that I would use for real, especially because I could just regenerate it if I have to update the video. This is a serious time saver.
How much would it cost?
My fully-produced course module has 25,000 characters of script and the Starter plan is $5 for 30,000 characters per month. That means to produce the entire course with an AI voice would be around $22 (for the Pro tier) and $0.30 per 1000 characters after.
I'd say not bad at all considering it took me 2h20m to record a 20-minute demo-heavy module. It wouldn't get rid of all the time, I'd still need to record the demos themselves but that takes way less time (and I can go faster).
Maybe for a future installment, I'll try to incorporate a full workflow with ElevenLabs – I actually have a non-client video in mind I need to do that I don't want to be a pain to maintain and it's a short video, so it could be a good candidate.
Here's an example of a workflow incorporating Rachel to storyboard a video
The Good
- Rachel and Josh are the best built-in voices
- The voice quality is the most natural I've come across
- It can joke without sounding weird
- The price isn't that bad for a lot of content
- You can view your past generations to download them
The Bad
- You can't provide any hints on where or how to emphasize (bold, italic, etc.)
- You can still tell it's AI if you listen close enough
- You can't teach it how to pronounce words, you have to adjust the script
- Your own voice is only going to be as good as the input
- Regenerating the same script uses up credits
The Lovely
- It has an API so you could create automated text-to-speech workflows
- You can adjust the voice quality and settings
- You can train your own voices
This is wild and I'm really excited to see more and more powerful services like this.
Have a lovely day,
Kamran